Teil 2: Die Maschinen lernen
Jan. 22, 2026
KI, ML
Das Internet und das stetige Wachstum der Rechenleistung ermöglichten es, alternative Ansätze zur künstlichen Intelligenz zunehmend effizient zu demonstrieren. Lange Zeit spielten diese Methoden jedoch nur eine untergeordnete Rolle im KI-Forschungsfeld und hinterließen aufgrund technischer Einschränkungen keinen nachhaltigen Eindruck. Mit der Zeit wurde jedoch klar, dass es unmöglich ist, die Welt vollständig mithilfe expliziter Regeln zu beschreiben. Natürliche Sprache ist hochkomplex, und Ausnahmen treten häufiger auf als feste Regeln. Anstelle von Regeln begannen Forscher daher, Maschinen Wahrscheinlichkeiten und statistische Zusammenhänge lernen zu lassen.
Heute nehmen wir es kaum noch bewusst, doch KI-Systeme sind längst Teil unseres Alltags. Empfehlungssysteme (Netflix, YouTube, Spotify), Spamfilter, Autovervollständigung in Texten, Kredit-Scoring bei Banken und viele weiter Anwendungen beruhen auf denselben Prinzipien.
Maschinelles Lernen
Zwischen den 1990er- und 2010er-Jahren kam es zu einer grundlegenden Verschiebung in KI. Wie in Teil 1 beschrieben, basierten frühere Ansätze der symbolischen KI auf explizit programmierten Wissenbasen und Regeln. Symbolische KI stieß jedoch bei komplexen Aufgaben schnell an ihre Grenzen, da es praktisch unmöglich ist, sämtliches relevantes Wissen und alle möglichen Sonderfälle manuell zu kodieren.
Heute werden diese klassischen Ansätze als GOFAI (oder Good Old-Fashioned Artificial Intelligence) bezeichnet. Ab den 2000er-Jahren setzen sich zunehmend andere Methoden als Mainstream durch, davon waren bereits seit den 1950er-Jahren bekannt, hatten aber lange Zeit keine ausreichenden technischen Voraussetzungen. Diese Ansätze sind heute unter dem Begriff Maschinelles Lernen (Machine Learning) zusammengefasst. Erneut spielten Spiele eine zentrale Rolle in der Entwicklung der KI.
Das Damespiel
Der Begriff Machine Learning wurde 1959 von Arthur Samuel, einem Forscher bei IBM, geprägt. Er verwendete ihn in seinem Artikel Some Studies in Machine Learning Using the Game of Checkers (Einige Studien im maschinellen Lernen mit dem Spiel der Checker).
 Samuel demonstriert sein Programm auf IBM 7090 in 1959. Quelle.
Samuel demonstriert sein Programm auf IBM 7090 in 1959. Quelle.
Samuel stand vor einem praktischen Problem: er wollte ein Programm entwickeln, das Damespiel beherrscht, war er jedoch kein Meisterspieler. Ihm fehlte das Expertenwissen, um alle relevanten Regeln (WENN-DANN) zu programmieren, die einen menschlichen Großmeister gewinnen helfen. Stattdessen verfolgt er einen anderen Ansatz. Samuel definierte maschinelles Lernen als:
Ein Verfahren, bei dem Computer die Fähigkeit erhalten, aus Erfahrung zu lernen, ohne für jede Situation explizit programmiert zu werden.
Anstatt jeden möglichen Zug fest zu kodieren, gab er der Maschine die Möglichkeit, ihr Spielverhalten selbstständig zu verbessern.
Sein Programm bestand aus mehreren Komponenten: - einem Vorausschauverfahren (look-ahead procedure), das eine Funktion ist, um mögliche zukünftige Spielstellungen zu rechnen; - einem Auswendiglernen (rote learning), bei dem bereits gesehene Stellungen gespeichert wurden; - einer Verallgemeinerung (generalization), bei der das System aus vergangenen Erfahrungen abstrakte Muster ableitete.
Das Programm wurde so aufgebaut, dass es gegen sich selbst spielte. Dabei traten zwei Versionen desselben Systems gegeneinander an, bezeichnet als Alpha und Beta. Nach jedem Spiel bewertete ein neutraler Teil des Programms die relative Spielstärke von Alpha im Vergleich zu Beta. Wenn Alpha gewann, wurden aktuelle Bewertungskoeffizienten von Alpha zu Beta gegeben. Wenn Beta gewann, wurden Koeffizienten von Alpha angepasst. Diese Koeffizienten werden als Gewichte bezeichnet.
Gewichte
Gewichte sind ein zentrales Konzept moderner KI. Eine Maschine "bildet sich eine Meinung", indem sie eine Bewertungsfunktion berechnet. Samuels Programm betrachtete das Spielbrett und musste einschätzen, wie gut eine bestimmte Stellung ist, etwa auf einer Skala von −100 bis +100. Dazu verwendete es verschiedene Parameter ():
- : Anzahl der eigenen Damen;
- : Anzahl der gegnerischen Figuren;
- : Kontrolle des Spielbrettzentrums.
Die Bewertung erfolgte mithilfe eines Polynom: Die Koeffizienten (weights) sind die Gewichte. Sie bestimmen, wie wichtig ein bestimmter Parameter für die Gesamtbewertung ist. Wenn = 10 und = 1, bewertet das Programm eine Dame haben wichtiger ist, als die Kontrolle des Zentrums. Negative Gewichte kennzeichnen Parameter, die als nachteilig gelten.
Zu Beginn setzte Samuel die Gewichte zufällig. Entsprechend schlecht spielte das Programm. Nach jeder Partie analysierte das Programm jedoch, warum es verloren hatte, und passte die Gewichte so an, dass ähnliche Fehler in Zukunft seltener auftreten. Lernen bedeutet hier nichts anderes als die schrittweise Anpassung der Gewichte, um den Fehler zu minimieren.
Das Modell
Dadurch hielt das Programm Gewichte in seinem Speicher, die eine konzentrierte Form von Erfahrung darstellen. Anhand seines Modelles kann das Programm den Wert einer Stellung vorhersagen. Das System bewertet die Situation und entscheidet: "Die Situation führt mit der Wahrscheinlichkeit von 70% zum Sieg". Das Polynom, das eine Bewertung berechnet, und Gewichtetabelle sind das KI-Modell in Samuels Damespielsystem.
Ein Modell ist eine mathematische Abstraktion der Realität. Die Hauptaufgabe jedes KI-Modelles besteht darin, mithilfe Eingabedaten ein Ereignis vorherzusagen. 1959 war dies ein einfaches Polynom mit mehreren Variablen. Heute sind es neurale Netzwerke: komplexe Kombinationen von Polynomen mit Milliarden von Parametern. Das Grundkonzept ist jedoch desselbe. Die Form des Polynoms () bestimmt die Architektur des Systems, und das Modell ist dieses Polynom mit konkret gelernten Gewichte (z. B. , ). Die Wahl des Modells hängt von Aufgaben und von Ansätzen des Lernens ab.
1962 gelang es Samuels Programm, einen der besten Damespieler der USA zu besiegen. Damit wurde erstmals demonstriert, dass ein Computer durch Erfahrung und ohne explizite Programmierung von Expertenwissen einen Menschen in einer intellektuellen Aufgabe übertreffen kann.
Lernparadigmen
Nach Jahrzehnten der Entwicklung etablierte sich eine Reihe grundlegender Ansätze und Methoden, die bis heute das Fundament nahezu aller modernen KI-Anwendungen bilden. In Artificial Intelligence: A Modern Approach von Russell und Norvig hängt Arten des Lernens von mehreren Faktoren ab, wird jedoch meist nach der Art des verfügbaren Feedback unterschieden. Daraus ergeben sich drei grundlegende Paradigmen: überwachtes Lernen, unüberwachtes Lernen und bestärkendes Lernen.
Weitere relevante Faktoren sind: - Welche Komponente des Systems verbessert (gelernt) werden soll. Beispielweise lernt eine KI, die als Taxifahrer fungiert, Wahrnehmung (Vision): KI lernt, einen Bus vom Lkw zu unterscheiden (Eingabe: Bild, Ausgang: Markierung). Oder sie lernt Entscheidungsfindung: Wann bremsen? - Welche Vorkenntnisse das System bereits besitzt. - Welche Darstellung für die Daten und die Komponente verwendet wird. Das betrifft die Merkmale der Eingabedaten (Features), die Beschreibung von Objekten für das System sowie deren interne Struktur.
Unüberwachtes Lernen (Unsupervised Learning)
Bei diesem Ansatz arbeitet das Modell mit unmarkierten Daten. Es gibt keine korrekten Antworten und kein explizites Feedback. Das Ziel ist es, Strukturen, Abhängigkeiten und Gesetzmäßigkeiten in den Daten zu entdecken. Die häufigste Aufgabe des unüberwachten Lernens ist das Clustering, also die Aufteilung der Daten in Gruppen.
Algorithmen des unüberwachten Lernens werden eingesetzt, wenn die Markierung der Daten aufwendig oder teuer ist. Ein Vorteil des unüberwachten Lernens besteht darin, dass es keine strukturierte Daten benötigt. Durch geringeren Anforderungen an die verwendeten Daten kann das System unbekannte Strukturen in den Eingabedaten entdecken. Dadurch können in der Zukunft weitere Daten auf der Grundlage identifizierter Mustern strukturiert und untersucht werden.
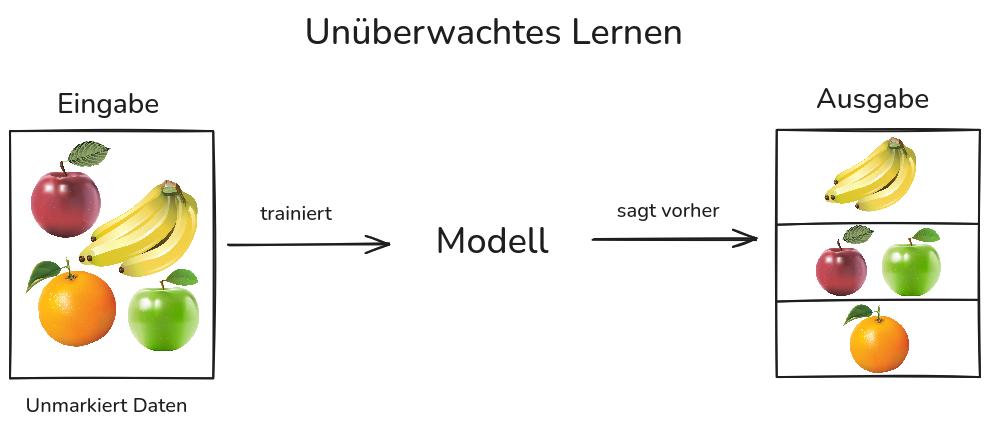
Beispielweise kann ein Taxiführungssystem von Verkehrssituationen in "leichter Verkehr" und "Stau" gruppieren, ohne dass diese Daten zuvor von einem Menschen markiert wurden.
Ein wichtiger Algorithmus in diesem Vorgehen ist der Erwartungs-Maximierungs-Algorithmus (kurz EM-Algorithmus). Das Kernidee ist es, iterativ die Modellparameter so anzupassen, dass sie die beobachteten Daten bestmöglich widerspiegeln. Ein typisches Anwendungsbeispiel ist die Vorbereitung von Datensätzen für das überwachte Lernen.
Überwachtes Lernen (Supervised Learning)
Bei einem überwachten Lernen wird das Modell mit zuvor markierten Datensätzen trainiert. Jede Eingabe ist mit einer gewünschten Ausgabe versehen. Der Lernprozess beginnt mit der Analyse der Trainingsdaten, wobei das Modell Regelmäßigkeiten zwischen Eingaben und Ausgaben erkennt. Die Ausgaben des Modells werden dabei durch die vorgegebenen Zielwerte überwacht.
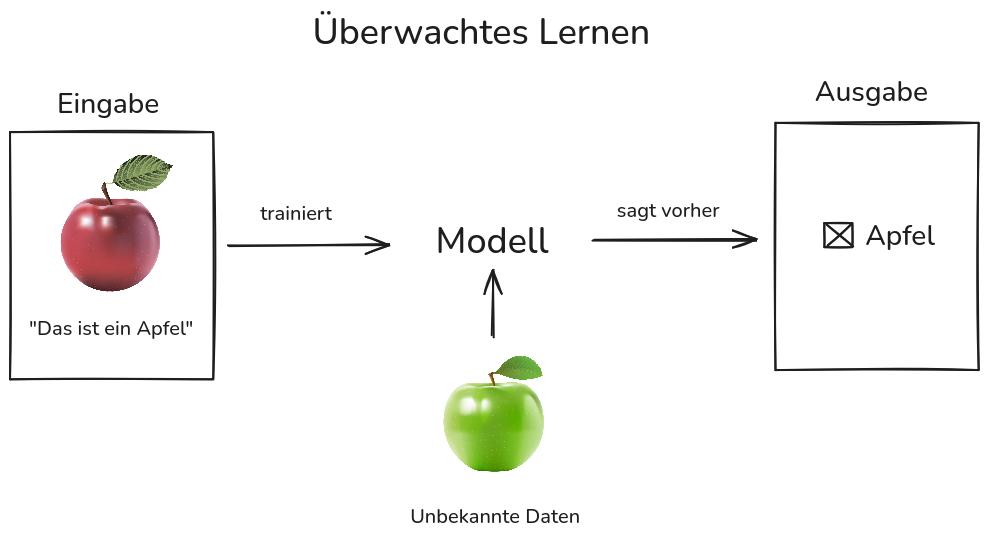
Überwachtes Lernen wird für Aufgaben der Regression und Klassifikation verwendet. Bei einer Regression sagt das Modell ein numerischen Wert voraus, etwa eine Temperatur oder einen Preis. Bei einer Klassifikation ordnet es ein Objekt einer vordefinierte Klassen, z. B. ob eine E-Mail Spam ist oder nicht. In Beispiel des Taxiführungssystems: wären dies Bilder mit den Labels „Bus“ oder „kein Bus“.
Bestärkendes Lernen (Reinforcement Learning, RL)
Bestärkendes Lernen ist ein Verfahren, bei dem ein Programm (Agent) durch Interaktion mit einer Umgebung lernt und für erfolgreiche Handlungen Belohnungen erhält. Ziel is es, durch Versuch und Irrtum eine Strategie zu erlernen, die die kumulative Belohnung maximiert.
Beispielweise erhält ein autonomes Taxiführungssystem am Ende der Fahrt kein Trinkgeld, was als negatives Signal interpretiert werden kann. Oder im Schach erhält das Programm Punkte für einen Sieg, was signalisiert, dass seine Strategie erfolgreich war.
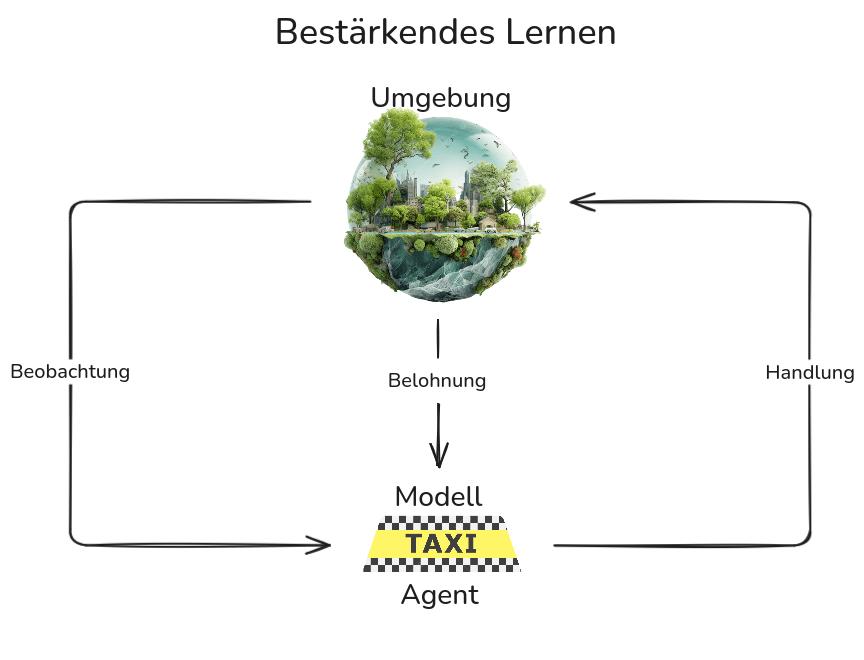
Dieser Ansatz wird bei der Entwicklung solcher Systeme verwendet wie Spiel-KI, Robotics, Verkehrssteuerung, Personalisierung und Werbung.
Die Wahl des Lernparadigmas bestimmt, welche mathematischen Modelle sinnvoll eingesetzt werden können. Beim überwachten Lernen verwenden wir Verfahren, die eine Funktion aus Eingaben und bekannten Ausgaben approximieren (z. B. lineare Regression, SVM, Entscheidungsbäume). Beim unüberwachten Lernen stehen keine Labels zur Verfügung; daher kommen Methoden zum Einsatz, die Strukturen in Daten erkennen (Clustering, PCA). Im Reinforcement Learning schließlich optimieren wir nicht eine Funktion, sondern ein Verhalten, weshalb Methoden wie Q-Learning oder Policy-Gradient dominieren.
In der Praxis existiert ein Kontinuum dieser Ansätze. Oft stehen nur wenige korrekte Beispielantworten zur Verfügung (semi-überwachtes Lernen), oder die Labels sind ungenau (etwa ein falsch angegebenes Alter in einem Datensatz). Deshalb kombinieren moderne ML-Systeme häufig mehrere Arten von Feedback.
Wiewohl in damalige Tage keine Klassifikation war, es lässt sich sagen, dass Samuels Damespielprogramm eine Mischung von überwachtem und bestärkendem Lernen verwendete, da Samuel Datensätze von Zuge menschlicher Meisterspieler nutzte. Die Maschine bezog diese Züge in die Bewertung von Stellungen ein. Allerdings gab es keinen Lehrer, der explizit sagte, welcher Zug gut oder schlecht ist. Das Programm erhielt eine Rückmeldung nur am Spielende: Sieg oder Niederlage.
Trotzdem war bis 1990-er Jahren die Nutzung des maschinellen Lernens noch nicht weit verbreitet. Die Möglichkeit des ML war begrenzt: Es gab keine großen Mengen digitaler Daten, und die Rechenleistung erlaubte keine effiziente Verarbeitung. Gleichzeitig wurde jedoch klar, dass es unmöglich ist, die Komplexität der Welt vollständig in Algorithmen zu beschreiben. In den 2000er-Jahren verlagerte sich der Fokus daher auf Daten. Das Internet stellte diese Daten in großem Umfang bereit.
Massendaten (Big Data)
Im Jahr 2009 veröffentlichten die Forscher von Google wie Alon Halevy, Peter Norvig, und Fernando Pereira den Artikel The Unreasonable Effectiveness of Data, der zu einem Manifest der Big-Data-Epoche wurde.
Der Titel des Artikels verweist auf den berühmten Essay des Physikers Eugene Wigner „Die unvernünftige Wirksamkeit der Mathematik in den Naturwissenschaften“.
Die Autoren behaupten, dass es in komplexen Bereiche wie der natürlichen Sprachverarbeitung (NLP) oft effektiver ist, einfache Algorithmen nach Mustern in sehr großen Mengen "verrauschter" Daten suchen zu lassen, anstatt zu versuchen, Sprache mit Hilfe tiefe linguistische Theorien zu erklären.
"...einfache Modelle und viele Daten sind besser als aufwändigere Modelle, die auf weniger Daten basieren."
Das Web als Korpus
Der Artikel hebt den Wert des Internets als Datenquelle hervor. Trotz der vielen Fehler in Webtexten wie Tippfehler, Slang, unvollständige Sätze, wird dies durch ihre massive Menge kompensiert. Die manuelle, qualitativ hochwertige Markierung von Daten ist zeit- und arbeitsintensiv. Stattdessen lassen sich semantische Beziehungen aus Suchanfragenstatistiken und strukturellen Textvorlagen (z. B. HTML) ableiten. Es ist oft sinnvoller, den gesamten verfügbaren Text des Internets zu nutzen, als kleine, sorgfältig ausgewählte Korpora wie das Wall-Street-Journal-Korpus.
Bei Milliarden von Sätzen überwiegt die statistische Bedeutung korrekter Konstruktionen die zufällige Fehler. Mit genügend Beispielen werden explizite generative Regeln für viele Aufgaben überflüssig.
Die Forscher zeigen, dass sich mit Beziehungslogik und einem Korpus von hudert Millionen Webseiten Fragen wie "welche Gemüsesorten helfen, Osteoporose vorzubeugen?" beantworten lassen, durch Verbindung miteinander zwei getrennte Tatsachen, dass "Kohl reich an Kalzium ist" und "Kalzium hilft, Osteoporose vorzubeugen", auch wenn diese Informationen auf unterschiedlichen Webseiten befinden.
Semantische Interpretation
Die Autoren betonen, dass Bedeutung aus Daten erschlossen werden kann, anstatt sie über Wörterbücher festzulegen. Das System betrachtet die Nachbarschaft eines Wortes (seinen Kontext) und bestimmt daraus seine Bedeutung.
Wenn das Wort "Apfel" beispielsweise in Verbindung mit Wörtern wie "gegessen", "saftig" oder "iPhone" auftritt, kann das System seine jeweilige Bedeutung ohne ein integriertes Wörterbuch erschließen. Wörter werden durch ihr Umfeld charakterisiert. Semantische Interpretation funktioniert mit großen Datensätze überraschend präzise.
Der Artikel markierte ein Paradigmenwechsel: KI muss nicht die tiefere Bedeutung des Textes verstehen wie ein Mensch, sondern ein System kann nächstes Wort mit hoher Wahrscheinlichkeit basierend Milliarden von Beispielen vorhersagen, entspricht das Ergebnis für den Nutzer dem "echten" Verständnis.
Die Modelle, die auf Big Data trainiert wurde, zeigten einen beeindruckender Erfolg. KI-Systeme haben sich fest in unserem Leben etabliert. Nichtsdestoweniger stießen statistische Modelle auf Kritik, insbesondere im Bereich der natürlichen Sprachverarbeitung.
Der Streit
Während des 150. Geburtstags des MIT machte Noam Chomsky auf dem Symposium Brains, Minds and Machines eine provokante Aussage. Der Wissenschaftler aus den Bereichen Linguistik, Kognitionswissenschaften und Informatik verspottete Forscher, die statistische Methode verwenden.
Seine Kernidee besteht darin, dass statistische Sprachmodelle lediglich das nächste Wort vorhersagen und Ergebnisse an Wahrscheinlichkeiten anpassen. Sie haben kein echtes Verständnis und fungieren als "Black Box", anstatt mit einer schlanken, eleganten Theorie zu arbeiten (wie etwa Newtons Gravitationsmodell). Chomsky argumentiert, dass die Modellierung grundsätzlich falsch sei: Menschen entscheiden nicht über das nächste Wort anhand von Wahrscheinlichkeitstabellen. Moderne statistische Ansätze seien nur ein technischer Hack und keine echte Wissenschaft.
Im selben Jahr 2011 veröffentlichte Peter Norvig seinen Essay On Chomsky and the Two Cultures of Statistical Learning, in dem er auf die Kritik von Chomsky antwortete.
Regeln wie "I wird vor E geschrieben, außer nach C" seien in vielen Fällen falsch, so Norvig. Statistische Modelle hingegen berücksichtigen Ausnahmen automatisch und spiegeln die Realität besser wider als explizite Regeln. Die Sprache sei ein stochastischer (zufälliger) Prozess, erzeugt von Milliarden Menschen, deswegen Wahrscheinlichkeiten eine angemessene Beschreibung linguistischer Phänomene darstellen und nicht bloß ein technischer Trick. Außerdem verarbeitet das menschliche Gehirn undeutliche Sprache in verrauschten Umgebungen ebenfalls probabilistisch, indem es die wahrscheinlichste Bedeutung rekonstruiert. Wenn die Welt komplex und verrauscht ist, muss auch das Modell komplex und für Menschen schwer lesbar sein. Für Norvig ist der Erfolg von Google Translate oder Suchmaschinen ein direkter Beweis dafür, dass statistische Modelle die Realität effektiv erfassen, auch wenn sie sich nicht in einfachen Formeln ausdrücken lassen.
Wenn wir die Entwicklungen der letzten 15 Jahre betrachten, sehen wir, dass die Realität nicht schwarz-weiß ist. Die statistische Schule setzte sich in praktischen Anwendungen durch: Übersetzung, Bilderkennung, Sprachmodelle. Chomskys Kritikpunkte bilden jedoch bis heute die Grundlage Forschungsfragen zu Erklärbarkeit, Robustheit und den Grenzen des maschinellen Lernens.
Gleichzeitig zeigte sich mit dem Wachstum der Datenmengen und der Rechenleistung, dass viele chomsky’sche Annahmen nicht mehr als zwingend gelten müssen. Maschinelles Lernen kann Strukturen erfassen, die früher als "unlernbar" galten, solange das Modell groß genug ist und die Datenmenge ausreichend.
Neurale Netze
Heutzutage sind die Daten unvernünftig viel. Ein Mensch kann relevanten Merkmale und Eigenschaften von Eingabedaten nicht mehr manuell beschreiben. Es wird daher eine Methode benötigt, die mit dem Datenumfang unbegrenzt "wachsen" kann.
Mit dem Erfolg großer statistischer Modelle und der Verfügbarkeit gewaltiger Datenmengen verschob sich der Fokus: von handgeschriebenen Regeln → zu statistischen Modellen → zu tiefen neuronalen Architekturen.
Während klassische Verfahren des maschinellen Lernens feste Strukturen benötigen und stark auf einzelne Aufgaben zugeschnitten sind, bieten neuronale Netze eine neue Ebene der Flexibilität. Sie können:
- Merkmale direkt aus Rohdaten lernen,
- komplexe, nichtlineare Zusammenhänge modellieren,
- Bilder, Sprache und Texte in abstrakte Repräsentationen überführen,
- und schließlich Aufgaben lösen, die zuvor als "nicht lernbar" galten.
Neuronale Netze sind genau jene "Black-Box" Modelle mit Milliarden von Parametern, über die Chomsky und Norvig gestritten haben. Sie lassen sich nicht einfach menschlich erklären ("Warum ist das so?"), liefern jedoch in vielen Fällen hochpräzise Vorhersagen.
Damit beginnt die Epoche des Deep Learning, eine Teilmenge des maschinellen Lernens, die in Teil 3 betrachtet wird - von Perzeptrons und Backpropagation bis hin zu modernen Transformer-Modellen.